Проанализируем модель угроз, содержащуюся в банке данных угроз ФСТЭК (доступную по адресу https://bdu.fstec.ru/files/documents/thrlist.xlsx ). Не будем анализировать её содержание и описание. Проанализируем только данные которые она содержит без критики её содержания. Для анализа будем испольовать общедоступные инструменты Python-библиотеку для анализа данных Pandas. Графики будем отрисовывать с помощью Python-библиотеки визуализации данных matplotlib.
from openpyxl import load_workbook
import pandas as pd
import matplotlib.pyplot as pltПо ссылке приведенной ниже скачиваем файл thrlist.xlsx, содержащий все актуальные угрозы. Далее для анализа исспользуем файл от 09.01.2020. Я удалил не нужную первую строку файла все остальное не менял. Далее читаем файл с помощью функции read_excel.
df=pd.read_excel('./Downloads/thrlist.xlsx')Переименуем все столбцы для удобного обращения с данными:
df.columns = ['id', 'name', 'description', 'threat_source', 'object', 'conf','integrity', 'availability','date_include', 'data_change']Проверим типы данных:
df.dtypes
id int64
name object
description object
threat_source object
object object
conf int64
integrity int64
availability int64
date_include datetime64[ns]
data_change datetime64[ns]
dtype: objectВажно проверить качество данные которые у Вас есть с помощь встроенных метода и isna() для определения пропущенных значений.
print(df.isna().sum())
id 0
name 0
description 0
threat_source 2
object 0
conf 0
integrity 0
availability 0
date_include 0
data_change 0
dtype: int64Для проведения дальнейших расчетов нам необходимо вычилить следующие данные:
Видим что в столбце threat_source есть 2 незаполненных значения. Нам нужно либо их отбросить либо заполнить. Посмотрим какие это угрозы:
lost_treat_source=df[df['threat_source'].isna() == True]
print(lost_treat_source)
id name \
141 142 Угроза приостановки оказания облачных услуг вс...
147 148 Угроза сбоя автоматического управления системо...
description threat_source \
141 Угроза заключается в возможности снижения каче... NaN
147 Угроза заключается в возможности возникновения... NaN
object conf integrity \
141 Системное программное обеспечение, аппаратное ... 0 0
147 Информационная система, система разграничения ... 1 0
availability date_include data_change
141 1 2015-03-20 2019-02-11
147 1 2015-03-20 2019-02-11Итак мы имеем дело с 142 и 148 угрозами из банка данных ФСТЭК: 142 "Угроза приостановки оказания облачных услуг вследствие технических сбоев" Угроза заключается в возможности снижения качества облачных услуг (или даже отказа в их оказании конечным потребителям) из-за возникновения технических сбоев хотя бы у одного из поставщиков облачных услуг (входящих в цепь посредников при оказании облачных услуг их конечному потребителю), а также из-за возникновения существенных задержек или потерь в каналах передачи данных, арендуемых потребителем или поставщиками облачных услуг. Данная угроза обусловлена слабостями процедуры контроля за выполнением технического обслуживания и соблюдением режимов функционирования технических средств облачной информационной системы. Реализация данной угрозы возможна при условии отсутствия механизмов резервирования средств обработки, хранения и передачи информации, входящих в состав облачной информационной системы. В данном случае видимо можно рассматривать Внешнего нарушителя со средним потенциалом - работника поставщика облачных усуг.
148 "Угроза сбоя автоматического управления системой разграничения доступа хранилища больших данных" Угроза заключается в возможности возникновения ситуаций, связанных c ошибками автоматического назначения пользователям прав доступа (наделение дополнительными полномочиями, ошибочное наследование, случайное восстановление «неактивных» учётных записей т.п.). Данная угроза обусловлена слабостями мер контроля за большим количеством (от тысячи, а в некоторых случаях и до нескольких миллионов) учётных записей пользователей со стороны администраторов безопасности. Реализация данной угрозы возможна при условии возникновения сбоев или ошибок в работе системы разграничения доступа хранилища больших данных В данном случае речь идет о Внутреннем нарушителе со средним потенциалом - администратором безопасности. Поясненеие: Это не администратор системы и не разработчик поэтому я оценил его потенциал как средний.
Добавим для 142 угрозы Внешнего нарушителя со средним потенциалом, а для 148 Внутреннего нарушителя со средним потенциалом.
df.loc[141, 'threat_source'] = 'Внешний нарушитель со средним потенциалом'
df.loc[147, 'threat_source'] = 'Внутренний нарушитель со средним потенциалом'
print(df.isna().sum())
id 0
name 0
description 0
threat_source 0
object 0
conf 0
integrity 0
availability 0
date_include 0
data_change 0
dtype: int64Посчитаем некоторые значения для построения графиков:
all_threat_count = len(df)
print('Количество угроз в текущей базе: '+ str(all_threat_count))
threat_C= len(df[df['conf']==1])
print('Количество угроз, воздействующих на конфиденциальность: ' + str(threat_C))
threat_C_only= len(df[(df['conf']==1) & (df['integrity']==0) & (df['availability']==0)])
print('Количество угроз, воздействующих только на конфиденциальность: ' + str(threat_C_only))
threat_I= len(df[df['integrity']==1])
print('Количество угроз, воздействующих на целостность: ' + str(threat_I))
threat_I_only= len(df[(df['conf']==0) & (df['integrity']==1) & (df['availability']==0)])
print('Количество угроз, воздействующих только на целостность: ' + str(threat_I_only))
threat_A= len(df[df['availability']==1])
print('Количество угроз, воздействующих на доступность: ' + str(threat_A))
threat_A_only= len(df[(df['conf']==0) & (df['integrity']==0) & (df['availability']==1)])
print('Количество угроз, воздействующих только на доступность: ' + str(threat_A))
threat_all_CIA= len(df[(df['conf']==1) & (df['integrity']==1) & (df['availability']==1)])
print('Количество угроз, воздействующих на КЦД: ' + str(threat_all_CIA))Количество угроз в текущей базе: 216
Количество угроз, воздействующих на конфиденциальность: 141
Количество угроз, воздействующих только на конфиденциальность: 39
Количество угроз, воздействующих на целостность: 134
Количество угроз, воздействующих только на целостность: 14
Количество угроз, воздействующих на доступность: 154
Количество угроз, воздействующих только на доступность: 154
Количество угроз, воздействующих на КЦД: 81
Ниже приведена круговая диаграмма распределением угроз по воздействию на конфиденциальность целостность и доступность(одна угроза может воздействовать на разные свойства информации в том числе на все).
no_CIA= all_threat_count-(threat_all_CIA+threat_C_only+threat_I_only+threat_A_only)
vals = [no_CIA, threat_all_CIA, threat_C_only, threat_I_only, threat_A_only ]
labels = ["Другие", "Воздействующие на КЦД", "Только конфидециальности", "Только целостности", "Только доступность"]
fig, ax = plt.subplots()
ax.pie(vals, labels=labels, autopct='%1.1f%%')
ax.axis("equal")
plt.title('Процентное соотношение угроз по воздействию на КЦД')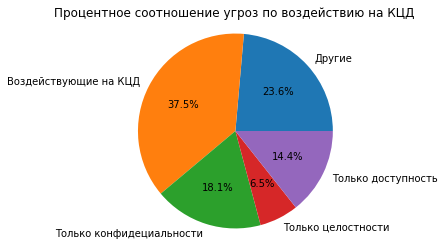
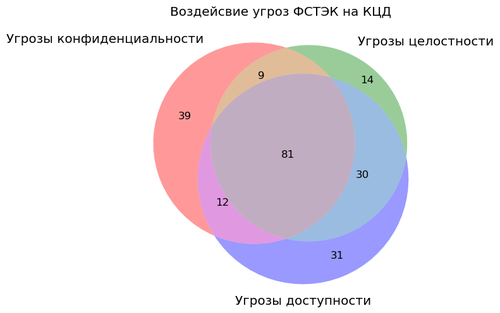
Теперь нарисуем диаграмму Эйлера-Венна распределения угроз по воздействию на КЦД.
#пересечение множеств по КЦД
from matplotlib_venn import venn3
import matplotlib
from matplotlib.pyplot import figure
font = {'family' : 'sans',
'size' : 12}
matplotlib.rc('font', **font)
figure(num=None, figsize=(10, 6), dpi=100, facecolor='w', edgecolor='k')
# пересечение угроз конфиденциальности и целостности
threat_C_I = len(df[(df['conf']==1) & (df['integrity']==1) & (df['availability']==0)])
# пересечение угроз конфиденциальности и доступности
threat_C_A = len(df[(df['conf']==1) & (df['integrity']==0) & (df['availability']==1)])
# пересечение угроз целостности и доступности
threat_I_A = len(df[(df['conf']==0) & (df['integrity']==1) & (df['availability']==1)])
venn3(subsets = (threat_C_only, threat_I_only, threat_C_I, threat_A_only,threat_C_A,threat_I_A,threat_all_CIA),
set_labels = ('Угрозы конфиденциальности', 'Угрозы целостности', 'Угрозы доступности'), alpha = 0.4 )
plt.title('Воздейсвие угроз ФСТЭК на КЦД')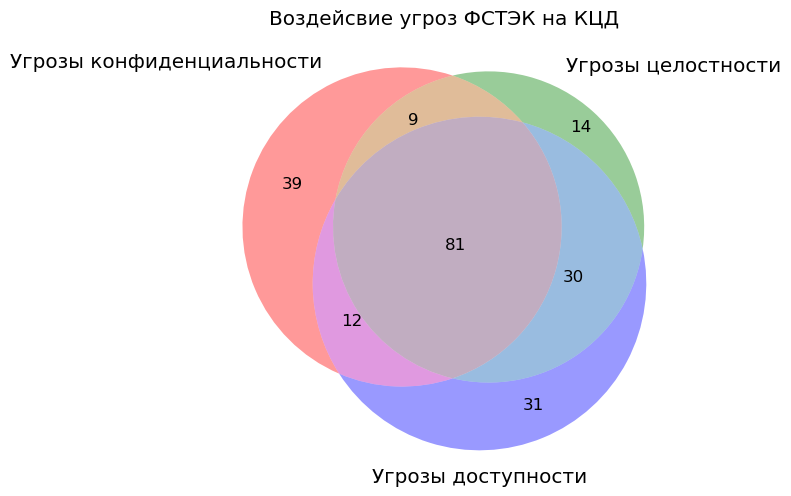
Рассчитаем значения по источнику уроз из банка данных угроз ФСТЭК для использования в дальнейшем анализе.
intruder_min_in_only = len(df[df['threat_source']=='Внутренний нарушитель с низким потенциалом'])
print('Количество угроз только с источником внутренний нарушитель с низким потенциалом: ' + str(intruder_min_in_only))
intruder_min_in_all = len(df[df['threat_source'].str.contains("Внутренний нарушитель с низким потенциалом", na=False)])
print('Общее количество угроз внутреннего нарушителя с низким потенциалом: ' + str(intruder_min_in_all))
intruder_mid_in_only = len(df[df['threat_source']=='Внутренний нарушитель со средним потенциалом' ])
print('Количество угроз только с источником внутренний нарушитель со средним потенциалом: ' + str(intruder_mid_in_only))
intruder_mid_in_all = len(df[df['threat_source'].str.contains('Внутренний нарушитель со средним потенциалом', na=False) ])
print('Общее количество угроз с источником внутренний нарушитель со средним потенциалом: ' + str(intruder_mid_in_all))
intruder_high_in_only = len(df[df['threat_source']=='Внутренний нарушитель с высоким потенциалом'])
print('Количество угроз внутреннего нарушителя с высоким потенциалом: ' + str(intruder_high_in_only))
intruder_high_in_all = len(df[df['threat_source'].str.contains('Внутренний нарушитель с высоким потенциалом', na=False)])
print('Общее количество угроз с источником внутреннего нарушителя с высоким потенциалом: ' + str(intruder_high_in_all))
intruder_min_out_only = len(df[df['threat_source']=='Внешний нарушитель с низким потенциалом'])
print('Количество угроз только с источником внешний нарушитель с низким потенциалом: ' + str(intruder_min_out_only))
intruder_min_out_all = len(df[df['threat_source'].str.contains("Внешний нарушитель с низким потенциалом", na=False)])
print('Общее количество угроз внешний нарушителя с низким потенциалом: ' + str(intruder_min_out_all))
intruder_mid_out_only = len(df[df['threat_source']=='Внешний нарушитель со средним потенциалом' ])
print('Количество угроз только с источником внешний нарушитель со средним потенциалом: ' + str(intruder_mid_out_only))
intruder_mid_out_all = len(df[df['threat_source'].str.contains('Внешний нарушитель со средним потенциалом', na=False) ])
print('Общее количество угроз с источником внешний нарушитель со средним потенциалом: ' + str(intruder_mid_out_all))
intruder_high_out_only = len(df[df['threat_source']=='Внешний нарушитель с высоким потенциалом'])
print('Количество угроз внешний нарушителя с высоким потенциалом: ' + str(intruder_high_out_only))
intruder_high_out_all = len(df[df['threat_source'].str.contains('Внешний нарушитель с высоким потенциалом', na=False)])
print('Общее количество угроз с источником внешний нарушителя с высоким потенциалом: ' + str(intruder_high_out_all))Количество угроз только с источником внутренний нарушитель с низким потенциалом: 35
Общее количество угроз внутреннего нарушителя с низким потенциалом: 91
Количество угроз только с источником внутренний нарушитель со средним потенциалом: 16
Общее количество угроз с источником внутренний нарушитель со средним потенциалом: 53
Количество угроз внутреннего нарушителя с высоким потенциалом: 3
Общее количество угроз с источником внутреннего нарушителя с высоким потенциалом: 3
Количество угроз только с источником внешний нарушитель с низким потенциалом: 36
Общее количество угроз внешний нарушителя с низким потенциалом: 87
Количество угроз только с источником внешний нарушитель со средним потенциалом: 26
Общее количество угроз с источником внешний нарушитель со средним потенциалом: 64
Количество угроз внешний нарушителя с высоким потенциалом: 8
Общее количество угроз с источником внешний нарушителя с высоким потенциалом: 12
Отобразим данные ввиде круговой диаграммы с отображением процентного соотношения угроз в зависимости от источника.
no_individyual= all_threat_count-(intruder_min_in_only+intruder_mid_in_only+intruder_high_in_only+intruder_min_out_only+intruder_mid_out_only+intruder_high_out_only)
vals = [no_individyual, intruder_min_in_only, intruder_mid_in_only, intruder_high_in_only, intruder_min_out_only, intruder_mid_out_only, intruder_high_out_only]
labels = ["Другие сочетания", "Вн. нар. низкий пот.", "Вн. нар. средний пот.", "Вн. нар. высокий пот.", "Внеш. нар. низкий пот.", "Внеш. нар. средний пот.", "Внеш. нар. высокий пот."]
fig, ax = plt.subplots()
ax.pie(vals, labels=labels, autopct='%1.1f%%', wedgeprops={'lw':1, 'ls':'--','edgecolor':"k"}, rotatelabels=False)
ax.axis("equal")
plt.title('Источники угроз в базе данных угроз ФСТЭК')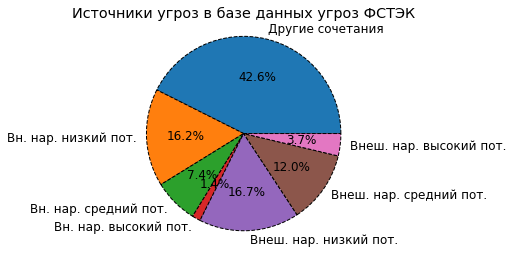
Поскольку угрозы могут иметь несколько источников то покажем количество угроз из различных источников.
vals = [intruder_min_in_all, intruder_mid_in_all, intruder_high_in_all, intruder_min_out_all, intruder_mid_out_all, intruder_high_out_all]
labels = [ "Вн. нар. низкий пот.", "Вн. нар. средний пот.", "Вн. нар. высокий пот.", "Внеш. нар. низкий пот.", "Внеш. нар. средний пот.", "Внеш. нар. высокий пот."]
plt.barh(labels , vals)
plt.title('Количество угроз из различных источников')
plt.ylabel('Источники угроз')
plt.xlabel('Количество угроз')
Теперь нарисуем диаграмму Эйлера-Венна распределения угроз по источникам в зависимости от статуса внешний или внутренний нарушитель.
#пересечения внешних с внутренними.
from matplotlib_venn import venn2
figure(num=None, figsize=(10, 6), dpi=100, facecolor='w', edgecolor='k')
#все угрозы с внутренними нарушителями
all_in_threat = len(df[df['threat_source'].str.contains("Внутренний", na=False)])
#все угрозы с внешними нарушителями
all_out_threat = len(df[df['threat_source'].str.contains("Внешний", na=False)])
#все угрозы с внешними нарушителями
all_cross_threat = len(df[(df['threat_source'].str.contains("Внешний", na=False)) & (df['threat_source'].str.contains("Внутренний", na=False))])
venn2(subsets = (all_in_threat, all_out_threat, all_cross_threat), set_labels = ('Внутренний нарушитель', 'Внешний нарушитель'))
plt.title('Отношения между внутренними и внешними нарушителями')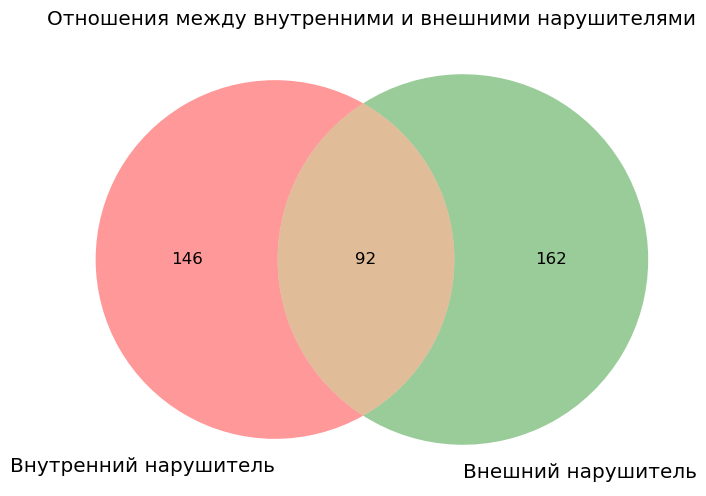
Покажем равзитие банка данных угроз во времени используя данные из банка данных. Так можно посмотреть с какой интенсивностью пополняется банк данных угроз ФСТЭК в различные годы.
from pandas.plotting import register_matplotlib_converters
plt.plot('date_include', 'id', data=df, color='tab:green')
plt.title('Пополнение угроз в банке данных угроз')
plt.ylabel('Количество угроз')
plt.xlabel('Год')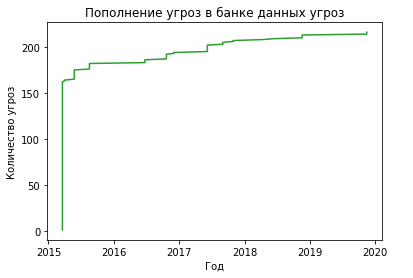
Поскольку база пополняется не часто то мы можем показать на рисунке конкретные даты пополнения и изменения угроза банка данных угроз ФСТЭК.
group_by_day = df.groupby([df['date_include'].dt.date]).count()
date= group_by_day.date_include
date.plot(kind='bar')
plt.ylabel('Количество угроз')
plt.xlabel('Дата добавления')
plt.title('Добавление угроз в базу данных угроз ФСТЭК')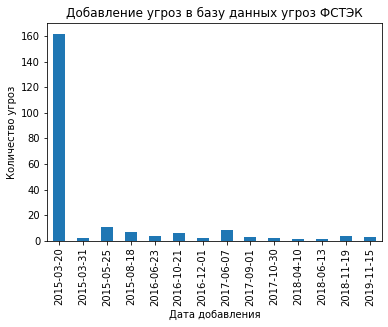
group_by_day = df.groupby([df['data_change'].dt.date]).count()
date= group_by_day.date_include
date.plot(kind='bar')
plt.ylabel('Количество угроз')
plt.xlabel('Дата изменения')
plt.title('Даты изменений угроз в базе данных угроз ФСТЭК')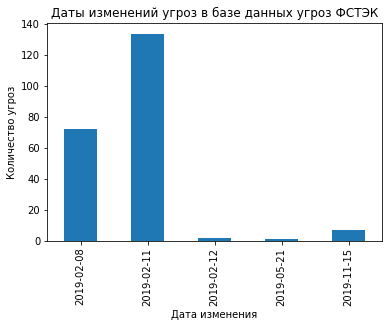
Далее необходимо проанализровать данные по Объекту воздействия. После его просмотра стало ясно, что значений там много а разделить их по разделителю(например, запятой) не получится. В столбце Объект воздействия ('object') имеются следующие проблемы: 1) Перечисления в скобках через запятую (если разделять данные по запятой то разделиться и содержимое скобок); 2) Деепричастные обороты; 3) Дублирование данных (например, написание через е и ё); К счастью таких данных не так много, поэтому можно не заморачиваться на регулярных выражениях а просто точечно поменять нужные ячейки.
Заменить объект 79 угрозы с "Виртуальные устройства хранения, обработки и передачи данных" на "Виртуальные устройства хранения/обработки и передачи данных"
Заменить описание объекта угрозы 164 "Облачная инфраструктура, созданная с использованием технологий виртуализации" на "Облачная инфраструктура, созданная с использованием технологий виртуализации".
Заключим деепричастный оборот в Объекте воздействия угрозы 180 в скобки: с "Технические средства воздушного кондиционирования, включая трубопроводные системы для циркуляции охлаждённого воздуха в ЦОД, программируемые логические контроллеры, распределённые системы контроля, управленческие системы и другие программные средства контроля", на : "Технические средства воздушного кондиционирования (включая трубопроводные системы для циркуляции охлаждённого воздуха в ЦОД), программируемые логические контроллеры, распределённые системы контроля, управленческие системы и другие программные средства контроля"
Заключим деепричастный оборот в Объекте воздействия угрозы 198 в скобки, поменяем: с "Система управления доступом, встроенная в операционную систему компьютера (программное обеспечение)" на "Система управления доступом (встроенная в операционную систему компьютера (программное обеспечение))".
Деепричастный оборот "Информационная система, иммигрированная в облако," который часто встречается в модели (например, угрозы 56, 134, 138, 141) заменим на "Информационноая система (иммигрированная в облако)".
Для угрозы 213 напишем "учетные данные пользователя" как в остальных случаях в таблице через букву Ё "учётные данные пользователя". Заменим с: "Системное программное обеспечение, микропрограммное обеспечение, учетные данные пользователя" на: "Системное программное обеспечение, микропрограммное обеспечение, учётные данные пользователя".
Для угрозы 210 необходимо поменять описание объекта "Аппаратное устройство, микропрограммное, системное и прикладное программное обеспечение", т.к. слово обеспечение относится к "микропрограммное, системное и прикладное" заменим на "Аппаратное устройство, микропрограммное обеспечение, системное программное обеспечение, прикладное программное обеспечение"
для угрозы 197 необходимо поменять описание объекта с "Информация, хранящаяся на компьютере во временных файлах (программное обеспечение)" на Информация (хранящаяся на компьютере во временных файлах (программное обеспечение))
для угрозы 170 необходимо поменять описание объекта с "Объект файловой системы" на "Объекты файловой системы" как в остальных случаях.
для угрозы 89 необходимо поменять описание объекта с "Системное программное обеспечение, использующее реестр, реестр" на "Системное программное обеспечение (использующее реестр), реестр"
Все перечисления в скобках сделаем через союз "и": Угроза 202 "Мобильные устройства (аппаратное устройство, программное обеспечение)" на "Мобильные устройства (аппаратное устройство и программное обеспечение)"
df.loc[179, 'object'] = 'Технические средства воздушного кондиционирования (включая трубопроводные системы для циркуляции охлаждённого воздуха в ЦОД), программируемые логические контроллеры, распределённые системы контроля, управленческие системы и другие программные средства контроля'
df.loc[212, 'object'] = 'Системное программное обеспечение, микропрограммное обеспечение, учётные данные пользователя'
df.loc[201,'object'] = 'Мобильные устройства (аппаратное устройство и программное обеспечение)'
df.loc[209,'object'] = 'Аппаратное устройство, микропрограммное обеспечение, системное программное обеспечение, прикладное программное обеспечение'
df.loc[197,'object'] = 'Система управления доступом (встроенная в операционную систему компьютера (программное обеспечение))'
df.loc[196,'object'] = 'Информация (хранящаяся на компьютере во временных файлах (программное обеспечение))'
df.loc[163,'object'] = 'Облачная инфраструктура (созданная с использованием технологий виртуализации)'
df.loc[198,'object'] = 'Мобильное устройство и запущенные на нем приложения (программное обеспечение и аппаратное устройство)'
df.loc[79,'object'] = 'Виртуальные устройства хранения/обработки и передачи данных'
df.loc[169,'object'] = 'Объекты файловой системы'
df.loc[88,'object'] = 'Системное программное обеспечение (использующее реестр), реестр'
df['object'] = df['object'].str.replace('Информационная система, иммигрированная в облако', 'Информационноая система (иммигрированная в облако)', regex=False, case = False)
df['object'] = df['object'].str.replace('информационная система, иммигрированная в облако', 'информационноая система (иммигрированная в облако)', regex=False, case = False)
df['object'] = df['object'].str.replace('информационная система, иммигрированная в облако,', 'информационноая система (иммигрированная в облако),', regex=False, case = False)Мы нормализовали данные теперь разобьём их по объектам воздействия.Для этого используем следующую функцию:
def tidy_split(df, column, sep='|', keep=False):
"""
Split the values of a column and expand so the new DataFrame has one split
value per row. Filters rows where the column is missing.
Params
------
df : pandas.DataFrame
dataframe with the column to split and expand
column : str
the column to split and expand
sep : str
the string used to split the column values
keep : bool
whether to retain the presplit value as it own row
Returns
-------
pandas.DataFrame
Returns a dataframe with the same columns as `df`.
"""
indexes = list()
new_values = list()
df = df.dropna(subset=[column])
for i, presplit in enumerate(df[column].astype(str)):
values = presplit.split(sep)
if keep and len(values) > 1:
indexes.append(i)
new_values.append(presplit)
for value in values:
indexes.append(i)
new_values.append(value)
new_df = df.iloc[indexes, :].copy()
new_df[column] = new_values
return new_df
extended_df = tidy_split(df, 'threat_source', sep=', ')
extend_df = tidy_split(extended_df, 'object', sep=', ')
extend_df['object'] = extend_df['object'].str.capitalize()Теперь наша талица содержит 760 угроз, каждая строка указывает на конкретный вид нарушителя и объект воздействия из базы ФСТЭК.
import random
import matplotlib.colors as mcolors
others_object= len(extend_df)-extend_df['object'].value_counts().sort_values(ascending=False).head(10).sum()
val = extend_df['object'].value_counts().sort_values(ascending=False).head(10)
others = len(extend_df)-extend_df['object'].value_counts().sort_values(ascending=False).head(10).sum()
vals = val.to_dict()
vals.update({'Другие':others})
colors = random.choices(list(mcolors.CSS4_COLORS.values()),k = len(vals))
fig, ax = plt.subplots()
ax.pie(vals.values(), labels=vals.keys(), autopct='%1.1f%%', colors = colors )
ax.axis("equal")
plt.title('Топ 10 объектов воздействия, с учетом разложения по нарушителям')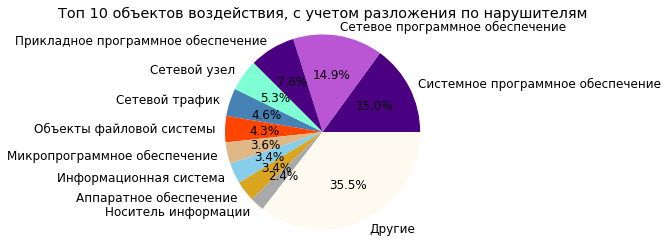
На этом анализ закончен, удалось проанализировать модель ФСТЭК по всем параметрам.